In the connected world of today, network availability is no longer a measurable advantage, it’s the baseline of reliability. Whether it’s a university campus, a data-intensive enterprise, or a multinational corporation, maintaining high availability (HA) in the network ensures continuous operations, minimal downtime, and stronger trust between systems and users.
In this article, I’ll walk through the key concepts, architecture design principles, and implementation strategies behind high-availability campus networks. I’ll unpack Cisco’s hierarchical design approach, the real technical challenges faced during simulations, and the lessons that shaped my engineering mindset.
To explore the full step-by-step lab and see the detailed network diagram, check out the article here:
https://amatoch.com/hands-on-lab-implementing-a-high-availability-campus-network-in-cisco-packet-tracer/”
Why High Availability Matters
High availability is all about designing networks that can’t easily fail — or more accurately, networks that continue to operate despite failures.
Organizations depend on their IT infrastructure to connect employees, services, and applications. When something fails — a switch, router, or link — the entire network should gracefully recover without users noticing. That’s the very definition of resilience.
According to research, downtime costs an average business thousands of dollars per hour. But the true cost isn’t just financial: it damages reliability, disrupts workflows, and limits trust in the IT infrastructure.
The goal of an HA system is not perfection — it’s predictable continuity. Every link, router, and switch has an expiration date; yet a properly architected network outlasts its weakest link because redundancy is built into every layer.
Understanding the Foundation: Cisco’s Hierarchical Model
Cisco’s hierarchical campus design model serves as the blueprint for reliable enterprise networks. It’s made up of modular layers, each serving specialized roles within the network. This modularity ensures simplicity and scalability — both essential for HA.
The Three Layers: Core, Distribution, and Access
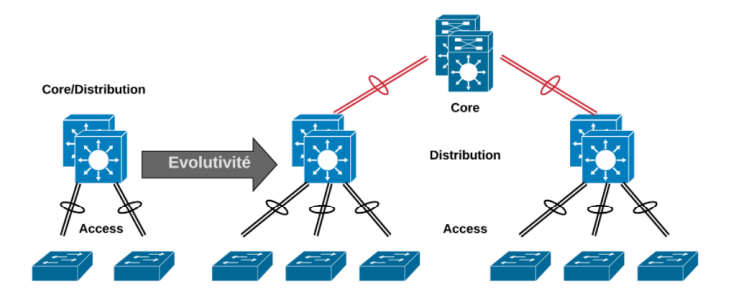
1. Core Layer — The Backbone of Speed
The core layer acts as the highway of your campus network. It provides high-speed connectivity and efficient data transportation between distribution layers.
Its golden rule: keep it fast and simple.
No complex ACLs, routing policies, or packet manipulation — just rapid, fault-tolerant forwarding.
Design Priorities for the Core:
- Redundant backbone switches.
- High-performance switching fabrics.
- Non-blocking architectures for maximum throughput.
- Avoid policy implementations that increase CPU load.
The core exists to forward traffic fast. Every microsecond counts at this layer.
2. Distribution Layer — The Control Point
This layer manages routing, access control, and policy enforcement. It connects the access switches to the core, handling VLAN segmentation, filtering, and redundancy between upstream and downstream traffic.
Design Priorities:
- Implement gateway redundancy (HSRP, VRRP, or GLBP).
- Aggregate links using EtherChannel for bandwidth and redundancy.
- Enforce policies (QoS, ACLs) closer to the source.
Think of this as the network’s decision-making layer — it’s where intelligence resides, ensuring conformance while maintaining connectivity.
3. Access Layer — The Edge of Connection
At the access layer, end devices such as PCs, printers, and access points connect. It’s the first and last point of user interaction.
Resiliency here starts at port security, VLAN design, and redundant uplinks toward the distribution layer.
Design Priorities:
- Dual uplinks from each access switch.
- Implementation of Rapid Spanning Tree Protocol (RSTP).
- Consistent VLAN segmentation per department or function.
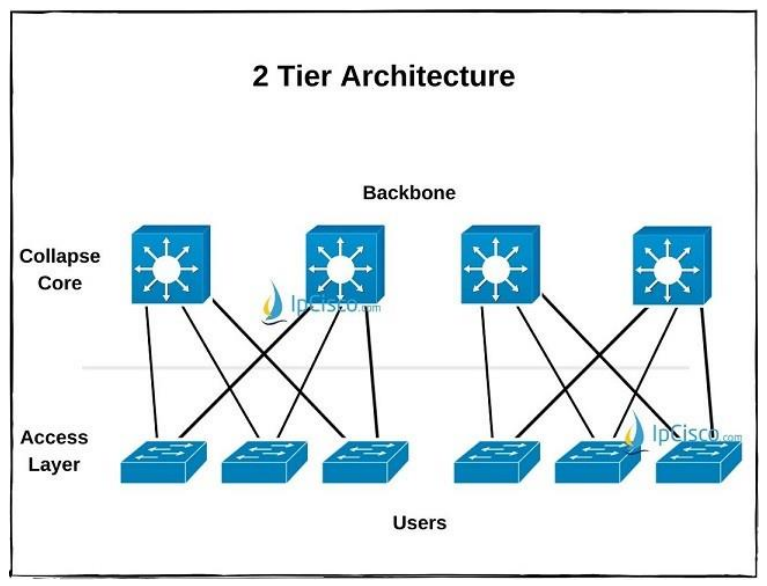
Simplifying Architecture: When to Choose the Two-Tier Design
Not every environment requires three layers. For smaller campuses or startup environments, the collapsed core model (two-tier architecture) simplifies deployment without sacrificing availability.
Here, the core and distribution layers merge, offering the same performance in a leaner footprint.
Use a 2-Tier Network When:
- There are fewer than 10 access switches.
- Inter-switch traffic is moderate.
- Cost or scalability beyond moderate growth isn’t a concern.
This design trades extreme modularity for efficiency and manageability.
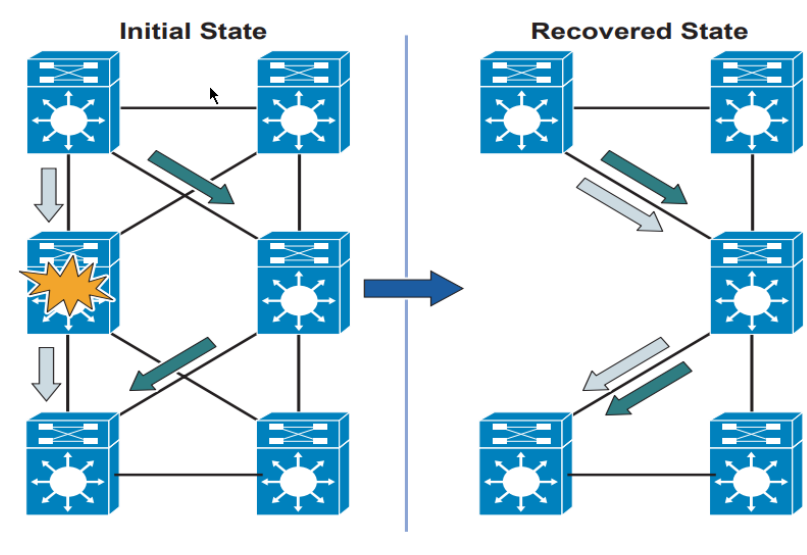
The Building Blocks of High Availability
1. Redundancy
Redundancy ensures there’s always a backup path or device ready to take over.
At each layer, you can incorporate both device redundancy (multiple switches/routers) and path redundancy (multiple physical links).
Example: Two distribution switches serving as redundant gateways for all access switches. If one fails, traffic automatically shifts to the secondary.
2. Load Balancing
Load balancing distributes network load across multiple paths or devices, enhancing both performance and availability.
Tools like EtherChannel and Equal-Cost Multi-Path (ECMP) routing achieve this by avoiding single-link bottlenecks.
3. Protocol Convergence
When a device or link fails, routing and switching protocols must adapt rapidly. Techniques like Rapid Spanning Tree Protocol (RSTP) and HSRP keep the downtime minimal.
A modern network design aims for convergence times below one second — anything slower causes visible interruptions to live systems, VoIP calls, or transactional services.
EtherChannel: Aggregated Redundancy
EtherChannel is one of the unsung heroes of HA design. By bundling multiple physical connections into one logical interface, it delivers two huge benefits:
- Bandwidth aggregation — effectively combining throughput.
- Link failure resilience — if one link fails, others immediately handle the load.
EtherChannel can operate in either static or dynamic modes (using protocols like PAgP or LACP).
It eliminates the problem of Spanning Tree Protocol (STP) blocking redundant links, as it treats all bundled interfaces as a single logical link.
Real-world takeaway:
EtherChannel turns a pair of 1 Gbps ports into a single, redundant 2 Gbps link — doubling performance while maintaining fault tolerance.
Rapid Spanning Tree Protocol (RSTP): Speeding Up Recovery
RSTP (IEEE 802.1w) improves upon traditional STP by dramatically reducing convergence time after topology changes.
In older setups, a failed link could cause a 30–50 seconds outage. With RSTP, this drops to under a second.
Key Mechanisms:
- Replaces listening/learning states with alternate and backup ports.
- Detects failure quickly using handshake messages instead of timers.
- Supports per-VLAN configurations in PVST+ environments.
RSTP should be enabled across all switches in high-availability topologies — especially where multiple redundant paths exist.
HSRP: Default Gateway Resilience
HSRP (Hot Standby Router Protocol) provides a virtual, fault-tolerant gateway for end devices.
How it works:
- Two or more routers (or L3 switches) share a virtual IP address.
- One acts as Active, another as Standby.
- If the active router fails, the standby takes over instantly.
Example Setup:
- Virtual IP: 192.168.1.1
- Router A (Active): handles traffic
- Router B (Standby): monitors Router A via hello messages.
- Failover time: less than one second.
HSRP vs. Others:
- VRRP: industry standard (multi-vendor).
- GLBP: load-balanced default gateway distribution.
For most Cisco and enterprise environments, HSRP’s robustness makes it the go-to solution.
Common Pitfalls & How to Avoid Them
1. Too Much Redundancy
Redundancy gone wrong causes complexity and admin overhead.
Rule: “Design to survive failure, not to exhaust hardware budgets.”
2. Ignoring Documentation
When topology grows, visual and logical documentation becomes critical.
Use tools like Draw.io or NetBox to maintain live topology maps.
3. Inconsistent Configuration
Identical link groups must mirror on both ends. Even minor mismatches (speed/duplex) break EtherChannel or create loops.
4. Neglecting Rapid Convergence Optimization
Default timers slow network recovery dramatically. Always fine-tune STP and HSRP timers for your environment.
Testing for Resiliency: The True Indicator of Design Quality
A network is only as good as its failure tests.
Here are key tests every engineer should perform:
| Test Scenario | Expected Outcome | Mechanism Used |
|---|---|---|
| Access switch uplink failure | No service loss | EtherChannel redistribution |
| Distribution-level router failure | Seamless gateway transition | HSRP failover |
| Broadcast loop injected | Minimal disruption | RSTP convergence |
| Power loss at access switch | Recovery via redundant path | Dual uplinks to distribution |
Each test confirms not only protocol success but design intent — ensuring theory and implementation align.
Lessons Learned: Engineering Beyond Configurations
Designing a highly available campus network taught me critical professional lessons that extend beyond the command line.
1. Think modularly.
A maintainable network is built in layers — each independent yet connected.
2. Simplicity scales best.
Redundancy must be simple enough to manage, else you replace one risk (failure) with another (complexity).
3. Always design for failure.
Your best work may never be noticed — until something goes wrong and your design withstands it.
4. Measure, document, iterate.
Networks evolve daily. Regular audits and topology reviews maintain integrity.
Applying These Concepts to Cloud Environments
While this project focused on physical campuses, the same concepts apply in AWS, Azure, or hybrid infrastructures.
- Redundant Availability Zones replace redundant switches.
- Load Balancers act as virtual HSRP mechanisms.
- Auto Scaling Groups mimic self-healing behavior through redundancy.
Resilience is universal — whether in a physical topology or a cloud VPC, availability relies on distribution, fault isolation, and rapid recovery mechanisms.
Conclusion
High availability isn’t just a feature — it’s a design mindset.
When architecture, redundancy, and operational strategies align, networks evolve from reactive systems into intelligent, self-healing ecosystems.
The beauty of engineering lies not only in creating something that works but in building something that continues working when everything else fails.
“Reliability is invisible when it works — and unforgettable when it doesn’t.”
Through careful redundancy design, protocol synergy, and relentless testing, high-availability architectures keep the digital world running, one failover at a time.
Further Reading
- Cisco: Hierarchical Network Design Model Documentation
- IEEE 802.1w: Rapid Spanning Tree Specifications – https://www.cisco.com/c/en/us/support/docs/lan-switching/spanning-tree-protocol/24062-146.html
- RFC 2281: HSRP for IP Networks – https://www.rfc-editor.org/rfc/rfc2281.html
- Cisco EtherChannel Configuration Guides
- Campus Network for High Availability Design Guide – https://www.cisco.com/c/dam/en/us/td/docs/solutions/Enterprise/Campus/HA_campus_DG/hacampus-dg.pdf
Leave a Reply
You must be logged in to post a comment.